
微调大模型,AMD MI300X就够了!跟着这篇博客微调Llama 3.1 405B,效果媲美H100
微调大模型,AMD MI300X就够了!跟着这篇博客微调Llama 3.1 405B,效果媲美H100随着 AI 模型的参数量越来越大,对算力的需求也水涨船高。
来自主题: AI资讯
5565 点击 2024-10-08 17:20
 搜索
搜索
随着 AI 模型的参数量越来越大,对算力的需求也水涨船高。
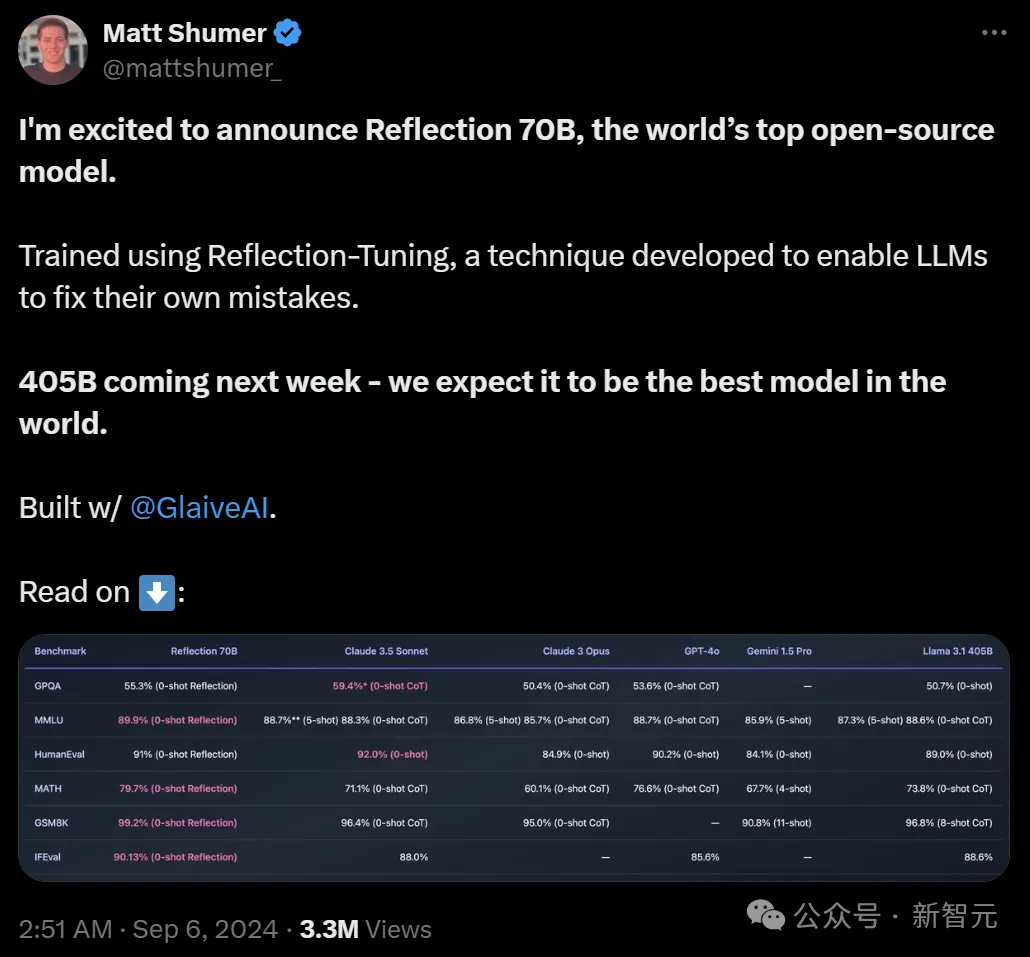
「开源新王」Reflection 70B,才发布一个月就跌落神坛了? 9月5日,Hyperwrite AI联创兼CEO Matt Shumer在X上扔出一则爆炸性消息—— 用Meta的开源Llama 3.1-70B,团队微调出了Reflection 70B。
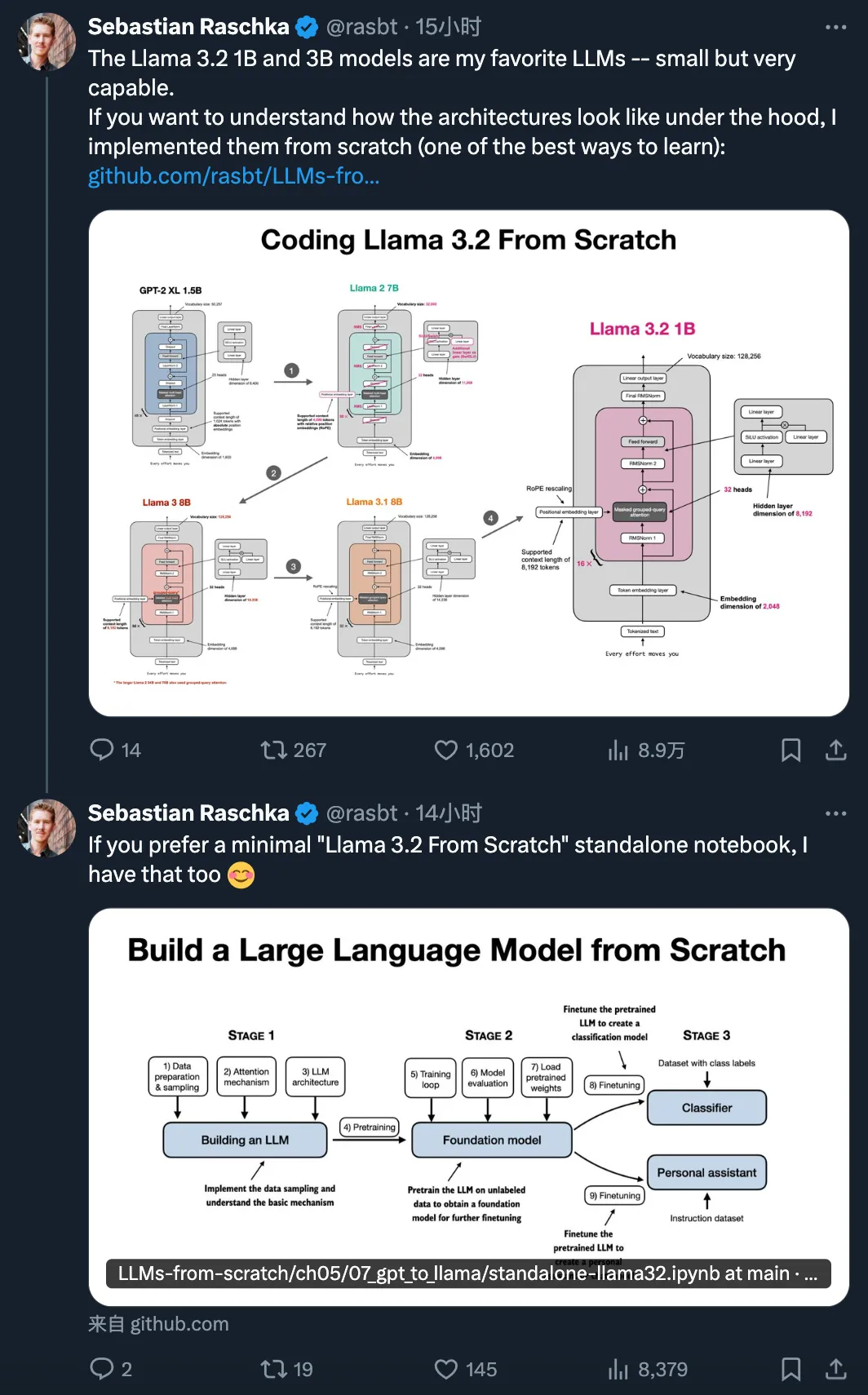
十天前的 Meta Connect 2024 大会上,开源领域迎来了可在边缘和移动设备上的运行的轻量级模型 Llama 3.2 1B 和 3B。两个版本都是纯文本模型,但也具备多语言文本生成和工具调用能力。Meta 表示,这些模型可让开发者构建个性化的、在设备本地上运行的通用应用 —— 这类应用将具备很强的隐私性,因为数据无需离开设备。

毫无预兆地,Meta版Sora——Movie Gen,就在刚刚抢先上线了!
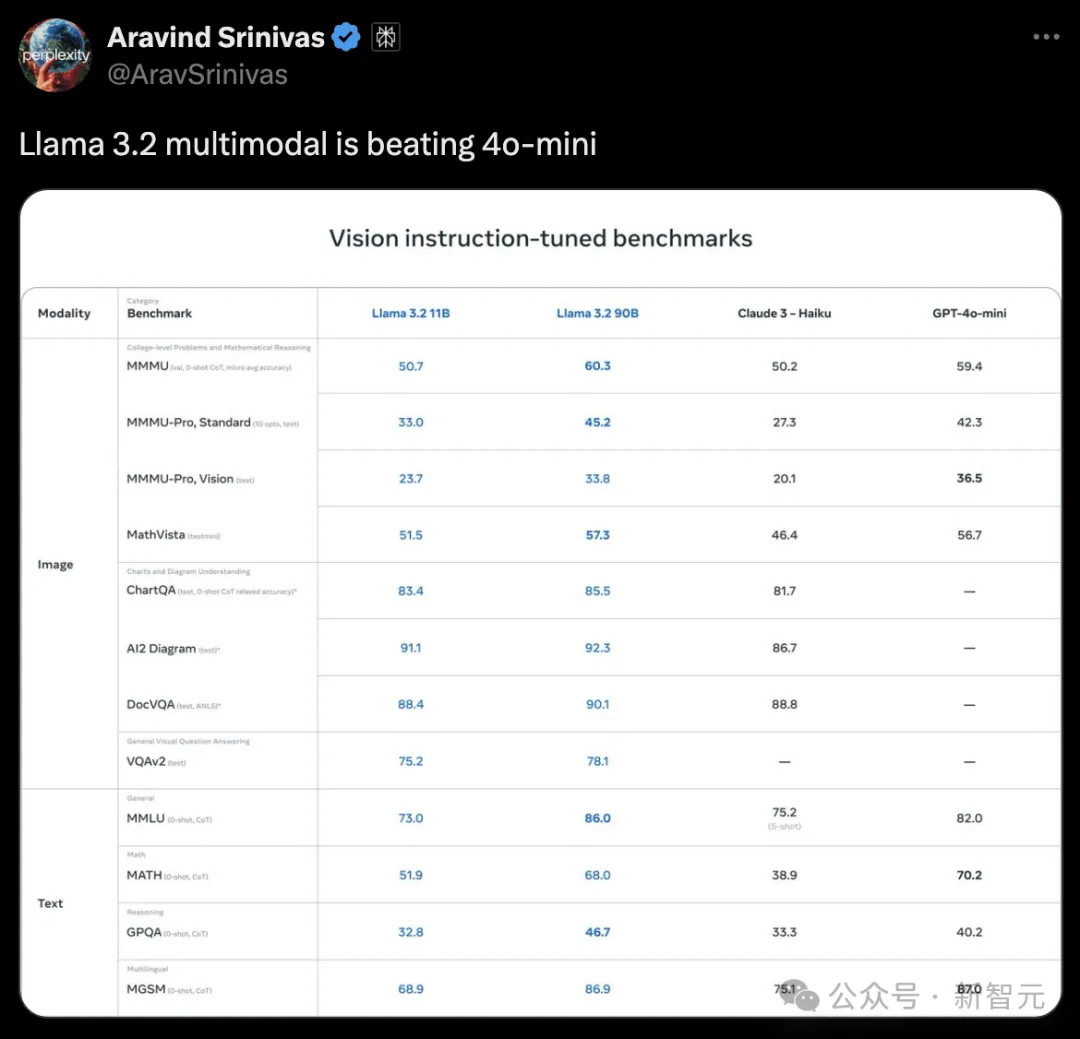
Meta首个理解图文的多模态Llama 3.2来了!这次,除了11B和90B两个基础版本,Meta还推出了仅有1B和3B轻量级版本,适配了Arm处理器,手机、AR眼镜边缘设备皆可用。

就在刚刚,小扎携掉最强AR眼镜Orion登场!Meta首款AR眼镜,苦研十年后,终于诞生了,成本高达10000美元。果然,小扎让我们离元宇宙又近了一步。这会是一次全新的范式转变吗?

Meta Connect 2024推出Quest 3S、Llama 3.2与AR眼镜Orion。

把Llama 3蒸馏到Mamba,推理速度最高可提升1.6倍!

如果可以使用世界上所有的算力来训练AI模型,会怎么样?近日,凭借发布了开源的Hermes 3(基于Llama 3.1)而引起广泛关注的Nous Research,再次宣布了一项重大突破——DisTrO(分布式互联网训练)。
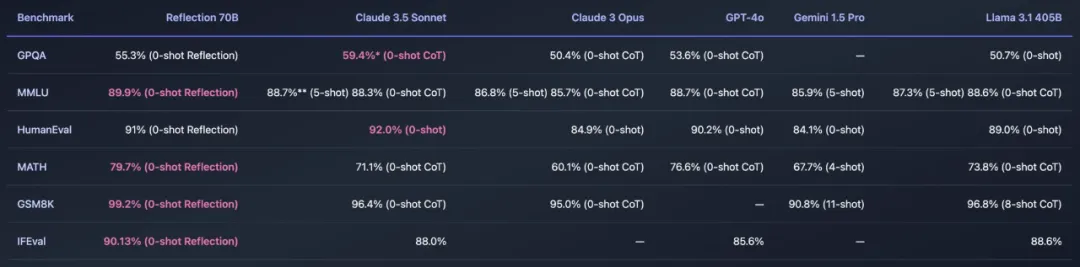
最近,开源大模型社区再次「热闹」了起来,主角是 AI 写作初创公司 HyperWrite 开发的新模型 Reflection 70B。